Googleの検索結果をスクレイピングしたい人「Googleの検索結果をスクレイピングしたけど、うまくいかない。スクレイピングのやり方を詳しく解説してほしいな」
こういった疑問にお答えします!
本記事を書いている私はシステムエンジニア(SE)としての経歴が9年ほど。機械学習のプロジェクトでPythonを使っています。
Googleの検索結果をスクレイピングしたいあなた。作業を自動化して作業負荷をなるべく下げようとする努力は、すばらしいですね。
でも、ネット上のスクレイピングのソースコードをそのままコピペしても、データを取得できなかった経験はありませんか?
私も同じ経験をしていまして、試行錯誤した結果、なんとかGoogleの検索結果をスクレイピングできるようなりました。
というわけで、本記事では、Googleの検索結果をスクレイピングしたいあなた向けに、現役SEの私が、PythonでGoogleの検索結果をスクレイピングする方法について、詳しく解説します。
本記事を読めばあなたも、Googleの検索結果をスクレイピングできるようになりますよ。
それでは早速行ってみましょう!
補足:Googleは検索結果のスクレイピングを認めてないので注意
こんな記事を書いておいてなんですが、Googleは検索結果のスクレイピングを認めていないので注意してください。
とは言いつつ、サーバーに高負荷がかからなければ、黙認されているというのが実体です。
スクレイピングはあくまで自己責任で行ってくださいね。
スポンサードサーチGoogleの検索結果をスクレイピングするために必要な知識【Python】

私が作成したGoogleの検索結果をスクレイピングするソースコードを解説するまえに、まずは、ソースコードを理解するために必要な知識について、お話ししますね。
- html、cssが読める
- Pythonのソースコードが読める
- Beautiful SoupがスクレイピングをするためのPythonのライブラリであることを知っている
上記の通り。3つ目は「そういったのを使うんだ。ふむふむ」くらいでOKです。html、css、Pythonがよくわからないなら、「Progate」で少し学習してみてください。
なお、本記事では、プログラムの実行環境として、「Google Colab」を利用しますので、Pythonの実行環境を用意する必要はありません。
「ソースコード解説はいいから、使い方だけ教えて!」という感じなら、下記からどうぞ。
Googleの検索結果をスクレイピングするソースコード解説【Python】

それでは、私が作成したGoogleの検索結果をスクレイピングするソースコードを解説していきます。
作成したプログラムのソースコード
作成したプログラムのソースコードは下記の通り。
#スプレットシートを利用するための準備
!pip install --upgrade -q gspread
from google.colab import auth
auth.authenticate_user()
import gspread
from oauth2client.client import GoogleCredentials
gc = gspread.authorize(GoogleCredentials.get_application_default())
#Googleの検索結果から上位サイトのtitle、h1、h2、h3、記事文字数を取得し、スプレッドシートへ出力
import sys
import requests
import bs4
import urllib.parse
import datetime
#置換用
def replace_n(str_data):
return str_data.replace('\n', '').replace('\r', '')
#文字列用
def concat_list(list_data):
str_data = ''
for j in range(len(list_data)):
str_data = str_data + replace_n(list_data[j].getText()).strip() + '\n'
return str_data.rstrip("\n")
#出力データ
output_data = []
#列名
columns = ['検索順位', 'url', 'titleタグ', 'h1タグ', 'h2タグ', 'h3タグ', '記事文字数']
output_data.append(columns)
#キーワードの指定
list_keyword = ['google検索結果', 'スクレイピング']
#検索順位取得処理
if list_keyword:
#Google検索の実施
search_url = 'https://www.google.co.jp/search?hl=ja&num=10&q=' + ' '.join(list_keyword)
res_google = requests.get(search_url)
res_google.raise_for_status()
#BeautifulSoupで掲載サイトのURLを取得
bs4_google = bs4.BeautifulSoup(res_google.text, 'html.parser')
#print(bs4_google.prettify())
link_google = bs4_google.select('.kCrYT > a') #Googleの仕様変更により修正が必要な場合がある
for i in range(len(link_google)):
#なんか変な文字が入るので除く
site_url = link_google[i].get('href').split('&sa=U&')[0].replace('/url?q=', '')
#URLに日本語が含まれている場合、エンコードされているのでデコードする
site_url = urllib.parse.unquote(urllib.parse.unquote(site_url))
if 'https://' in site_url or 'http://' in site_url:
#サイトの内容を解析
try:
res_site = requests.get(site_url)
res_site.encoding = 'utf-8'
except:
continue
bs4_site = bs4.BeautifulSoup(res_site.text, 'html.parser')
#データを初期化
title_site = ''
h1_site = ''
h2_site = ''
h3_site = ''
mojisu_site = 0
#データを取得
if bs4_site.select('title'):
title_site = replace_n(bs4_site.select('title')[0].getText())
if bs4_site.select('h1'):
h1_site = concat_list(bs4_site.select('h1'))
if bs4_site.select('h2'):
h2_site = concat_list(bs4_site.select('h2'))
if bs4_site.select('h3'):
h3_site = concat_list(bs4_site.select('h3'))
if bs4_site.select('body'):
mojisu_site = len(bs4_site.select('body')[0].getText())
#データをリストに入れておく
output_data_new = i+1, site_url, title_site, h1_site, h2_site, h3_site, mojisu_site
output_data.append(output_data_new)
#スプレットシートに出力する
table_data = output_data
row_len = len(table_data)
col_len = len(table_data[0])
now = datetime.datetime.now()
mojiretsu = ' '.join(list_keyword)
sheet_name = '[' + mojiretsu + ']' + '{0:%Y%m%d%H%M%S}'.format(now)
sh = gc.create(sheet_name)
worksheet = gc.open(sheet_name).sheet1
# 出力前にシートの行数を増やしておく
worksheet.add_rows(row_len)
# 出力先の指定はA1形式だけでなくセルの行と列番号でも指定できる
cell_list = worksheet.range(1, 1, row_len, col_len)
col_list = [flatten for inner in table_data for flatten in inner]
for cell, col in zip(cell_list, col_list):
cell.value = col
worksheet.update_cells(cell_list)作成したプログラムの概要
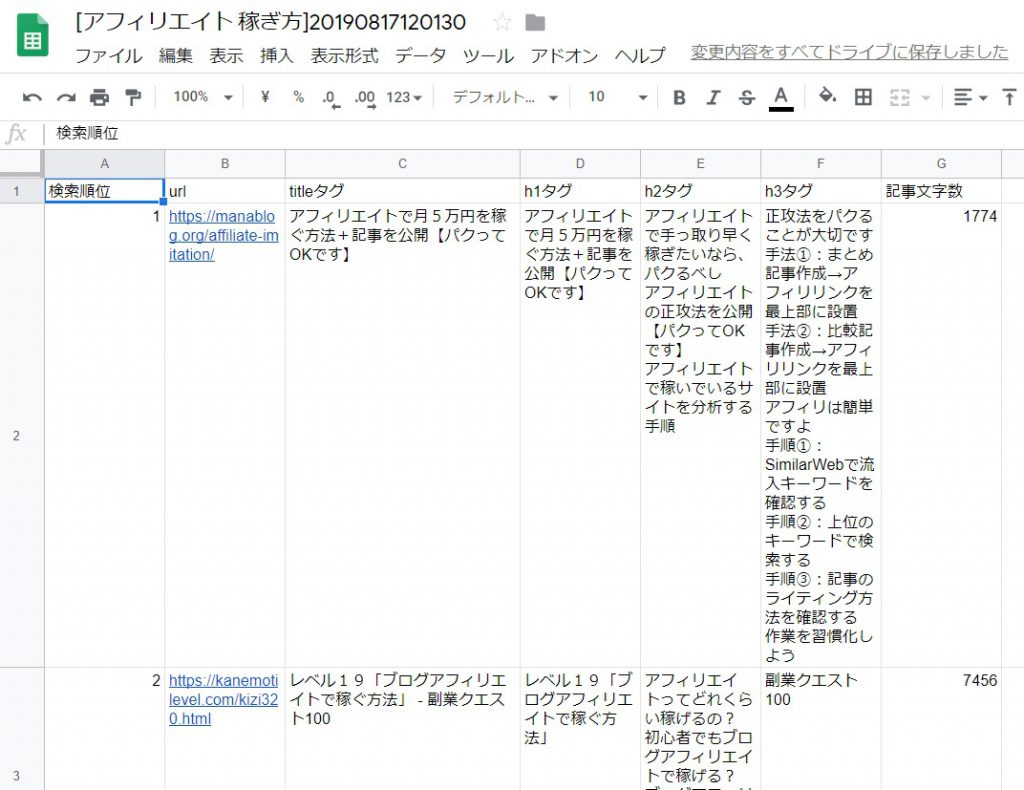
キーワードを設定し、プログラムを実行することで、Googleの検索結果1ページ目に表示される上位サイトの下記データを取得し、スプレッドシートへ出力します。
- URL
- titleタグ
- h1タグ
- h2タグ
- h3タグ
- 記事文字数
スプレッドシートへの出力結果は下記の通り。
作成したプログラムの解説
それでは次に作成したプログラムについて、順番に解説していきます。
※実行環境は「Google Colab」を想定しています。
スプレットシートを利用するための準備
#スプレットシートを利用するための準備
!pip install --upgrade -q gspread
from google.colab import auth
auth.authenticate_user()
import gspread
from oauth2client.client import GoogleCredentials
gc = gspread.authorize(GoogleCredentials.get_application_default())取得したデータは、Googleドライブ上のスプレッドシートへ出力するので、Googleドライブの認証を通しておきます。
また、Pythonでスプレッドシートを操作できるよう「gspread」ライブラリをインストールしておきます。
必要なライブラリをインポート
import sys
import requests
import bs4
import urllib.parse
import datetime- URLをリスクエストするために「requests」
- スクレイピングをするために「bs4」
- URLに日本語が含まれる可能性があるのでエンコード、デコードをするために「urllib.parse」
上記をインポートしておきます。
スプレッドシートに出力するためにデータ配列を作成
#出力データ
output_data = []
#列名
columns = ['検索順位', 'url', 'titleタグ', 'h1タグ', 'h2タグ', 'h3タグ', '記事文字数']
output_data.append(columns)出力するデータ用の配列を作成し、最初に列名をセットしておきます。
Googleの検索を行う
#キーワードの指定
list_keyword = ['Google検索結果', 'スクレイピング']
#検索順位取得処理
if list_keyword:
#Google検索の実施
search_url = 'https://www.google.co.jp/search?hl=ja&num=10&q=' + ' '.join(list_keyword)
res_google = requests.get(search_url)
res_google.raise_for_status()キーワードを指定して、URLを作成します。
そして、URLに対してrequestsを投げて、結果を取得します。
print(search_url)ちなみに、上記のようにprintを使って「search_url」変数の中身を見てみると下記のURLがセットされています。
https://www.google.co.jp/search?hl=ja&num=10&q=google検索結果 スクレイピング
Googleの検索結果をスクレイピングして上位サイトのURLを取得する
#BeautifulSoupで掲載サイトのURLを取得
bs4_google = bs4.BeautifulSoup(res_google.text, 'html.parser')
#print(bs4_google.prettify())
link_google = bs4_google.select('.kCrYT > a') #Googleの仕様変更により修正が必要な場合がある先ほど取得したrequestsの結果「res_google」をBeautiful Soupを使って、html化して、「bs4_google」に入れます。
print(bs4_google.prettify())上記の通り、printを使って中身を見てみましょう。
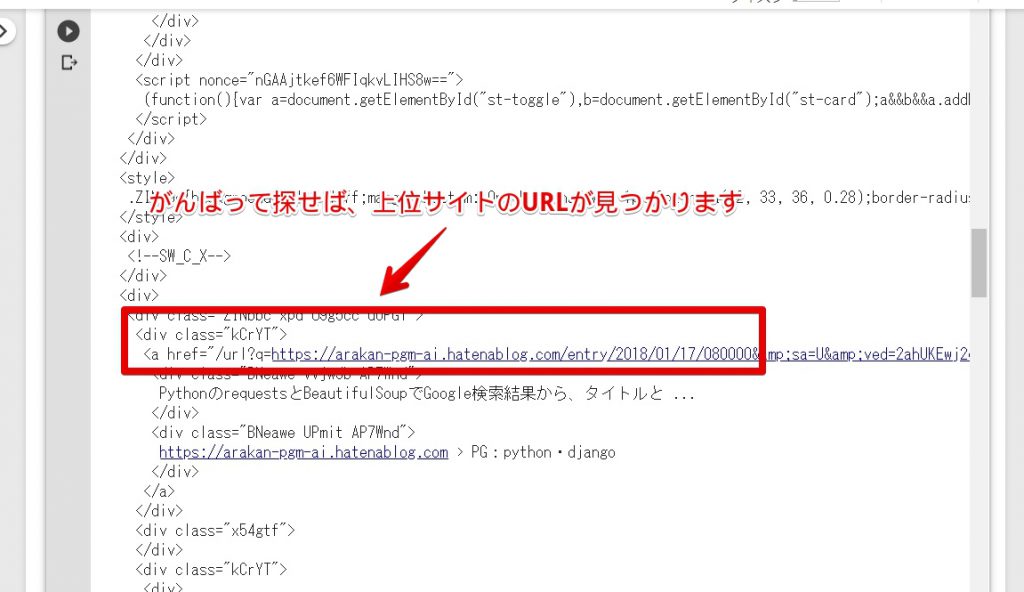
上記の通り、長いhtmlが表示されます。上位サイトのURLを取得したいので、がんばって探せば見つかります。
link_google = bs4_google.select('.kCrYT > a')class名が「kCrYT」なので、上記のソースの通り、スクレイピングで「class=”kCrYT”の中にあるリンクタグ」を取得して「link_google」に入れます。
他のサイトでは、「bs4_google.select(‘.r > a’)」で取得できると紹介されていますが、Googleに仕様が変わったようです。
今後もGoogleの仕様が変わる可能性があるので、結果を取得できない場合はclass名を確認するようにしましょう。
for i in range(len(link_google)):
print(link_google[i])「link_google」変数の中身を見てみましょう。上記ソースコードを実行してください。
<a href="/url?q=https://qiita.com/TeQuiLayy/items/a74f928426dcb013e1cd&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjAAegQIAxAB&usg=AOvVaw2uYi21EUtsuG54xbKrN6MS"><div class="BNeawe vvjwJb AP7Wnd">Google検索結果をスクレイピングするときは、User-Agentの設定に気を ...</div><div class="BNeawe UPmit AP7Wnd">https://qiita.com › Ruby</div></a>
<a href="/url?q=https://icedog-works.com/python-scraping&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjABegQIChAB&usg=AOvVaw3fsTatoAzrvhavLSmXu12m"><div class="BNeawe vvjwJb AP7Wnd">Python(パイソン)でGoogleの検索結果をスクレイピングする【コピペOK】</div><div class="BNeawe UPmit AP7Wnd">https://icedog-works.com › プログラミング › Python</div></a>
<a href="/url?q=https://note.mu/ta9to/n/n19f17932be86&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjACegQICRAB&usg=AOvVaw3FurQ9OEEPSe5ppgh554My"><div class="BNeawe vvjwJb AP7Wnd">GoogleのSERPS(検索結果ページ)をスクレイピングする|ta9to|note</div><div class="BNeawe UPmit AP7Wnd">https://note.mu › ta9to</div></a>
<a href="/url?q=https://tanuhack.com/python/google-scraping/&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjADegQICBAB&usg=AOvVaw30OGIh8InF8Mn0rByK6uBA"><div class="BNeawe vvjwJb AP7Wnd">[Python]Googleの検索結果をスクレイピングして、スプレッドシートに保存 ...</div><div class="BNeawe UPmit AP7Wnd">https://tanuhack.com › python › google-scraping</div></a>
<a href="/url?q=https://codeday.me/jp/qa/20190121/187010.html&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjAEegQIBxAB&usg=AOvVaw3qcVJTm5Vw-DXqRn0fZSoh"><div class="BNeawe vvjwJb AP7Wnd">Pythonを使用したGoogle検索結果のスクレイピングと解析 - コードログ</div><div class="BNeawe UPmit AP7Wnd">https://codeday.me › ...</div></a>
<a href="/url?q=https://helpcenter.octoparse.jp/hc/ja/articles/360015729034-Google%25E6%25A4%259C%25E7%25B4%25A2%25E3%2581%25AE%25E7%25B5%2590%25E6%259E%259C%25E3%2582%2592%25E3%2582%25B9%25E3%2582%25AF%25E3%2583%25AC%25E3%2582%25A4%25E3%2583%2594%25E3%2583%25B3%25E3%2582%25B0%25E3%2581%2599%25E3%2582%258B&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjAFegQIBBAB&usg=AOvVaw099c92pcpB2Y2s1aHa6qye"><div class="BNeawe vvjwJb AP7Wnd">Google検索の結果をスクレイピングする - スクレイピングツール | Octoparse</div><div class="BNeawe UPmit AP7Wnd">https://helpcenter.octoparse.jp › articles › 360015729034-Google検索の結...</div></a>
<a href="/url?q=https://www.rank50.net/note/1016&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjAGegQIARAB&usg=AOvVaw2J8YEwXpyqLLwPPu11mOD1"><div class="BNeawe vvjwJb AP7Wnd">Google検索結果スクレイピングツール : 検索順位チェックツール ...</div><div class="BNeawe UPmit AP7Wnd">https://www.rank50.net › note</div></a>
<a href="/url?q=https://arakan-pgm-ai.hatenablog.com/entry/2018/01/17/080000&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjAHegQIAhAB&usg=AOvVaw02c2tiRV9eGHuAcj0lTnGR"><div class="BNeawe vvjwJb AP7Wnd">PythonのrequestsとBeautifulSoupでGoogle検索結果から、タイトルと ...</div><div class="BNeawe UPmit AP7Wnd">https://arakan-pgm-ai.hatenablog.com › PG:python・django</div></a>
<a href="/url?q=https://teratail.com/questions/152124&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjAIegQIBhAB&usg=AOvVaw3G6507-91JdvOoWSFNtpBC"><div class="BNeawe vvjwJb AP7Wnd">Python 3.x - python3 / beautifulsoup / google検索結果スクレイピング ...</div><div class="BNeawe UPmit AP7Wnd">https://teratail.com › questions</div></a>
<a href="/url?q=http://trelab.info/python/python-google%25E6%25A4%259C%25E7%25B4%25A2%25E7%25B5%2590%25E6%259E%259C%25E3%2582%2592beautifulsoup%25E3%2581%25A7%25E3%2582%25B9%25E3%2582%25AF%25E3%2583%25AC%25E3%2582%25A4%25E3%2583%2594%25E3%2583%25B3%25E3%2582%25B0%25E3%2581%2597%25E3%2581%25A6%25E3%2580%2581%25E3%2582%25BF%25E3%2582%25A4%25E3%2583%2588/&sa=U&ved=2ahUKEwi7qOapr4vkAhWaGDQIHe9wC9wQFjAJegQIBRAB&usg=AOvVaw0Zweh3o1l0MD1bW2wb0J67"><div class="BNeawe vvjwJb AP7Wnd">[python] google検索結果をbeautifulsoupでスクレイピングして、タイトル ...</div><div class="BNeawe UPmit AP7Wnd">trelab.info › Python</div></a>上記の通り、リンクタグが取得できていますね。
上位サイトへアクセスしてタグのデータを取得する
for i in range(len(link_google)):
#なんか変な文字が入るので除く
site_url = link_google[i].get('href').split('&sa=U&')[0].replace('/url?q=', '')
#URLに日本語が含まれている場合、エンコードされているのでデコードする
site_url = urllib.parse.unquote(urllib.parse.unquote(site_url))
if 'https://' in site_url or 'http://' in site_url:
#サイトの内容を解析
try:
res_site = requests.get(site_url)
res_site.encoding = 'utf-8'
except:
continue
bs4_site = bs4.BeautifulSoup(res_site.text, 'html.parser')
#データを初期化
title_site = ''
h1_site = ''
h2_site = ''
h3_site = ''
mojisu_site = 0
#データを取得
if bs4_site.select('title'):
title_site = replace_n(bs4_site.select('title')[0].getText())
if bs4_site.select('h1'):
h1_site = concat_list(bs4_site.select('h1'))
if bs4_site.select('h2'):
h2_site = concat_list(bs4_site.select('h2'))
if bs4_site.select('h3'):
h3_site = concat_list(bs4_site.select('h3'))
if bs4_site.select('body'):
mojisu_site = len(bs4_site.select('body')[0].getText())
#データをリストに入れておく
output_data_new = i+1, site_url, title_site, h1_site, h2_site, h3_site, mojisu_site
output_data.append(output_data_new)取得したリンクタグをもとに、1サイトずつスクレイピングしてtitleタグ、h1タグ、h2タグ、h3タグ、文字数を取得しています。
for i in range(len(link_google)):
#なんか変な文字が入るので除く
site_url = link_google[i].get('href').split('&sa=U&')[0].replace('/url?q=', '')
#URLに日本語が含まれている場合、エンコードされているのでデコードする
site_url = urllib.parse.unquote(urllib.parse.unquote(site_url))リンクタグからURLを取得するのが結構大変なので、補足します。上記のソースコードにて下記処理を実施しています。
- hrefを取得
- 不要なパラメータを切り離し(&sa=U&以降は削除)
- 不要な文字(/url?q=)を削除
- 日本語がエンコードされているのでデコード
for i in range(len(link_google)):
print(link_google[i].get('href'))
print(link_google[i].get('href').split('&sa=U&')[0])
print(link_google[i].get('href').split('&sa=U&')[0].replace('/url?q=', ''))
print(urllib.parse.unquote(urllib.parse.unquote(link_google[i].get('href').split('&sa=U&')[0].replace('/url?q=', ''))))上記のソースコードを実行するとわかりやすいです。
/url?q=https://helpcenter.octoparse.jp/hc/ja/articles/360015729034-Google%25E6%25A4%259C%25E7%25B4%25A2%25E3%2581%25AE%25E7%25B5%2590%25E6%259E%259C%25E3%2582%2592%25E3%2582%25B9%25E3%2582%25AF%25E3%2583%25AC%25E3%2582%25A4%25E3%2583%2594%25E3%2583%25B3%25E3%2582%25B0%25E3%2581%2599%25E3%2582%258B&sa=U&ved=2ahUKEwjI09rKx4vkAhXbIDQIHQO7BEMQFjAFegQIBhAB&usg=AOvVaw2wJU9ZQq8DXCWiFI_qmFA6
/url?q=https://helpcenter.octoparse.jp/hc/ja/articles/360015729034-Google%25E6%25A4%259C%25E7%25B4%25A2%25E3%2581%25AE%25E7%25B5%2590%25E6%259E%259C%25E3%2582%2592%25E3%2582%25B9%25E3%2582%25AF%25E3%2583%25AC%25E3%2582%25A4%25E3%2583%2594%25E3%2583%25B3%25E3%2582%25B0%25E3%2581%2599%25E3%2582%258B
https://helpcenter.octoparse.jp/hc/ja/articles/360015729034-Google%25E6%25A4%259C%25E7%25B4%25A2%25E3%2581%25AE%25E7%25B5%2590%25E6%259E%259C%25E3%2582%2592%25E3%2582%25B9%25E3%2582%25AF%25E3%2583%25AC%25E3%2582%25A4%25E3%2583%2594%25E3%2583%25B3%25E3%2582%25B0%25E3%2581%2599%25E3%2582%258B
https://helpcenter.octoparse.jp/hc/ja/articles/360015729034-Google検索の結果をスクレイピングする結果は上記の通り、URLに日本語が含まれている場合は、デコードした結果を最終的に使用します。
URLさえちゃんと取得できれば、あとは、1サイトずつスクレイピングしてtitleタグ、h1タグ、h2タグ、h3タグ、文字数を取得するという感じです。
スクレイピングにて取得したデータをスプレッドシートへ出力する
#スプレットシートに出力する
table_data = output_data
row_len = len(table_data)
col_len = len(table_data[0])
now = datetime.datetime.now()
mojiretsu = ' '.join(list_keyword)
sheet_name = '[' + mojiretsu + ']' + '{0:%Y%m%d%H%M%S}'.format(now)
sh = gc.create(sheet_name)
worksheet = gc.open(sheet_name).sheet1
# 出力前にシートの行数を増やしておく
worksheet.add_rows(row_len)
# 出力先の指定はA1形式だけでなくセルの行と列番号でも指定できる
cell_list = worksheet.range(1, 1, row_len, col_len)
col_list = [flatten for inner in table_data for flatten in inner]
for cell, col in zip(cell_list, col_list):
cell.value = col
worksheet.update_cells(cell_list)最後に、上記のソースコードにて、スプレッドシートに取得した結果を出力します。
さいごに:スクレイピングを使っていろいろ自動化しよう
本記事では、Googleの検索結果をスクレイピングしたいあなた向けに、現役SEの私が、PythonでGoogleの検索結果をスクレイピングする方法について、詳しく解説しました。
これであなたも、Googleの検索結果をスクレイピングすることができますね!
本記事で紹介したソースコードをもとに、スクレイピングを使ってWebサイトの分析をいろいろと自動化してみてください。
本記事で紹介したプログラムが、あなたの役に立てば幸いです。
こんな感じで自分で作成したプログラムを公開しているので、ツイッターのフォローをお願いします。また、ブログを更新したら通知しています。



