
競合サイトの分析をしている人「アフィリエイトをやっている。競合サイトを分析するために、Googleの検索結果上位サイトのタイトルとかタグを確認しているけど、自動取得することはできないのかな?」
こういった疑問にお答えします!
本記事を書いている私はシステムエンジニア(SE)としての経歴が9年ほど。副業として、このKatsuhiroBlogを150日以上毎日更新しています。
競合サイトを分析しているあなた。ちゃんと競合の分析をし、戦略を立てて、アフィリエイトをやっているなんて、向上心があってすばらしいですね!
でも、競合サイトの分析をしようと
Googleでキーワード検索
↓
上位サイトを一つひとつ開いて、titleタグ、h1タグ、h2タグ、h3タグなどを確認
上記のような面倒くさい作業をやっていませんか?
こんな面倒くさい作業できればやりたくないですよね。
そこで、本記事では、競合サイトを分析しているあなた向けに、Googleの検索結果上位サイトのtitleタグ、h1タグなどを自動取得するプログラムを無料公開します。
本記事で公開するプログラムを使えば、Googleの検索結果の上位サイト10位の下記データを自動で取得することが可能です。
- URL
- titleタグ
- h1タグ
- h2タグ
- h3タグ
- 記事文字数
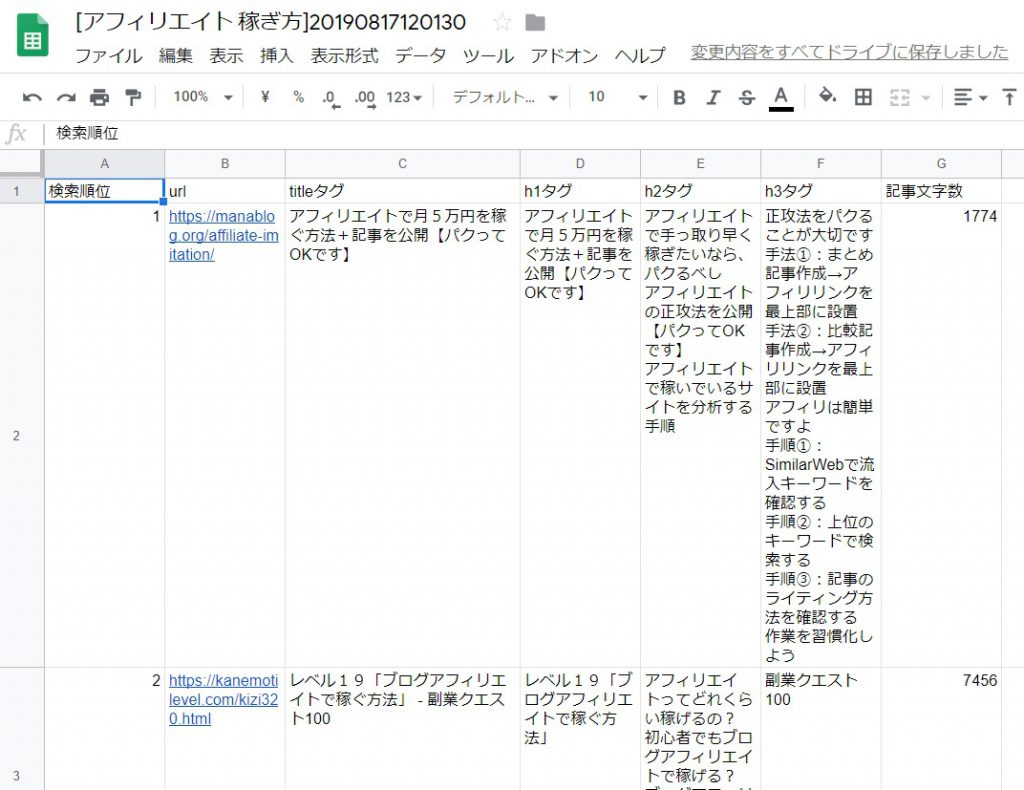
実際の取得結果は上記の通り。
※「アフィリエイト 稼ぎ方」をキーワードに検索した結果から取得しました。
プログラムと聞いて、「自分でもできるのかな?」と心配になる必要は一切ありません。
Googleのアカウントさえあれば、だれでもプログラムを使うことができますよ。
それでは早速いってみましょう!
スポンサードサーチ競合サイトのタグを自動取得する方法

競合サイトのタグを自動取得するために「ウェブスクレイピング」という技術を利用しました。
「ウェブスクレイピング」とは「Webサイトの情報を取得する技術」です。
本記事で紹介するプログラムでは、AI技術でよく使われている「Python」というプログラミング言語で「ウェブスクレイピング」を行っています。
Googleの検索結果をスクレイピングするプログラム公開
「プログラムさえ教えてくれれば、あとは自分でできるよ」というあなた向けに、まずは作成したプログラムを公開します。
#スプレットシートを利用するための準備
!pip install --upgrade -q gspread
from google.colab import auth
auth.authenticate_user()
import gspread
from oauth2client.client import GoogleCredentials
gc = gspread.authorize(GoogleCredentials.get_application_default())
#Googleの検索結果から上位サイトのtitle、h1、h2、h3、記事文字数を取得し、スプレッドシートへ出力
import sys
import requests
import bs4
import urllib.parse
import datetime
#置換用
def replace_n(str_data):
return str_data.replace('\n', '').replace('\r', '')
#文字列用
def concat_list(list_data):
str_data = ''
for j in range(len(list_data)):
str_data = str_data + replace_n(list_data[j].getText()).strip() + '\n'
return str_data.rstrip("\n")
#出力データ
output_data = []
#列名
columns = ['検索順位', 'url', 'titleタグ', 'h1タグ', 'h2タグ', 'h3タグ', '記事文字数']
output_data.append(columns)
#キーワードの指定
list_keyword = ['google検索結果', 'スクレイピング']
#検索順位取得処理
if list_keyword:
#Google検索の実施
search_url = 'https://www.google.co.jp/search?hl=ja&num=10&q=' + ' '.join(list_keyword)
res_google = requests.get(search_url)
res_google.raise_for_status()
#BeautifulSoupで掲載サイトのURLを取得
bs4_google = bs4.BeautifulSoup(res_google.text, 'html.parser')
#print(bs4_google.prettify())
link_google = bs4_google.select('.kCrYT > a') #Googleの仕様変更により修正が必要な場合がある
for i in range(len(link_google)):
#なんか変な文字が入るので除く
site_url = link_google[i].get('href').split('&sa=U&')[0].replace('/url?q=', '')
#URLに日本語が含まれている場合、エンコードされているのでデコードする
site_url = urllib.parse.unquote(urllib.parse.unquote(site_url))
if 'https://' in site_url or 'http://' in site_url:
#サイトの内容を解析
try:
res_site = requests.get(site_url)
res_site.encoding = 'utf-8'
except:
continue
bs4_site = bs4.BeautifulSoup(res_site.text, 'html.parser')
#データを初期化
title_site = ''
h1_site = ''
h2_site = ''
h3_site = ''
mojisu_site = 0
#データを取得
if bs4_site.select('title'):
title_site = replace_n(bs4_site.select('title')[0].getText())
if bs4_site.select('h1'):
h1_site = concat_list(bs4_site.select('h1'))
if bs4_site.select('h2'):
h2_site = concat_list(bs4_site.select('h2'))
if bs4_site.select('h3'):
h3_site = concat_list(bs4_site.select('h3'))
if bs4_site.select('body'):
mojisu_site = len(bs4_site.select('body')[0].getText())
#データをリストに入れておく
output_data_new = i+1, site_url, title_site, h1_site, h2_site, h3_site, mojisu_site
output_data.append(output_data_new)
#スプレットシートに出力する
table_data = output_data
row_len = len(table_data)
col_len = len(table_data[0])
now = datetime.datetime.now()
mojiretsu = ' '.join(list_keyword)
sheet_name = '[' + mojiretsu + ']' + '{0:%Y%m%d%H%M%S}'.format(now)
sh = gc.create(sheet_name)
worksheet = gc.open(sheet_name).sheet1
# 出力前にシートの行数を増やしておく
worksheet.add_rows(row_len)
# 出力先の指定はA1形式だけでなくセルの行と列番号でも指定できる
cell_list = worksheet.range(1, 1, row_len, col_len)
col_list = [flatten for inner in table_data for flatten in inner]
for cell, col in zip(cell_list, col_list):
cell.value = col
worksheet.update_cells(cell_list)上記の通り。コピペして好きに使ってください。
※「Google Colab」上で実行すれば、Googleドライブのマイドライブにスプレッドシートが作成されます。
うまく動かない場合(Googleの仕様変更)
プログラムがうまく動かない場合は、Googleの検索結果の仕様が変更された可能性があります。
#BeautifulSoupで掲載サイトのURLを取得
bs4_google = bs4.BeautifulSoup(res_google.text, 'html.parser')
#print(bs4_google.prettify())
link_google = bs4_google.select('.kCrYT > a') #Googleの仕様変更により修正が必要な場合がある上記の4行目(ハイライトを当てた行)にて、Googleの検索結果のサイトリンクを取得しているのですが、そのclass名が変更されているかもしれません。
3行目のコメントアウトを外して、プログラムを実行し、最新のclass名を確認のうえ、修正してみてください。
補足:あくまで自分が分析するためだけに使用してください
Googleは検索結果のスクレイピングを認めていないようなので、本記事で公開したプログラムを使うのは、実はグレーです。
とは言いつつ、Googleもある程度は黙認してくれるので、あくまで自分が競合サイトを分析するためだけに、使用してくださいね。
競合サイトのタグを自動取得するプログラムの使い方

それでは具体的な使い方について、一から解説します。
※Googleアカウントも持っていない場合は、作成をお願いします。
プログラムのダウンロード
まずはプログラムをダウンロードしてください。私のGoogleドライブ上で共有ファイルとして保存してあるので、下記からプログラムを開いてください。
https://colab.research.google.com/drive/12h7bhR0lHS-T8u7dRgSYTUxczdeJxT3O
プログラムをGoogleドライブに保存
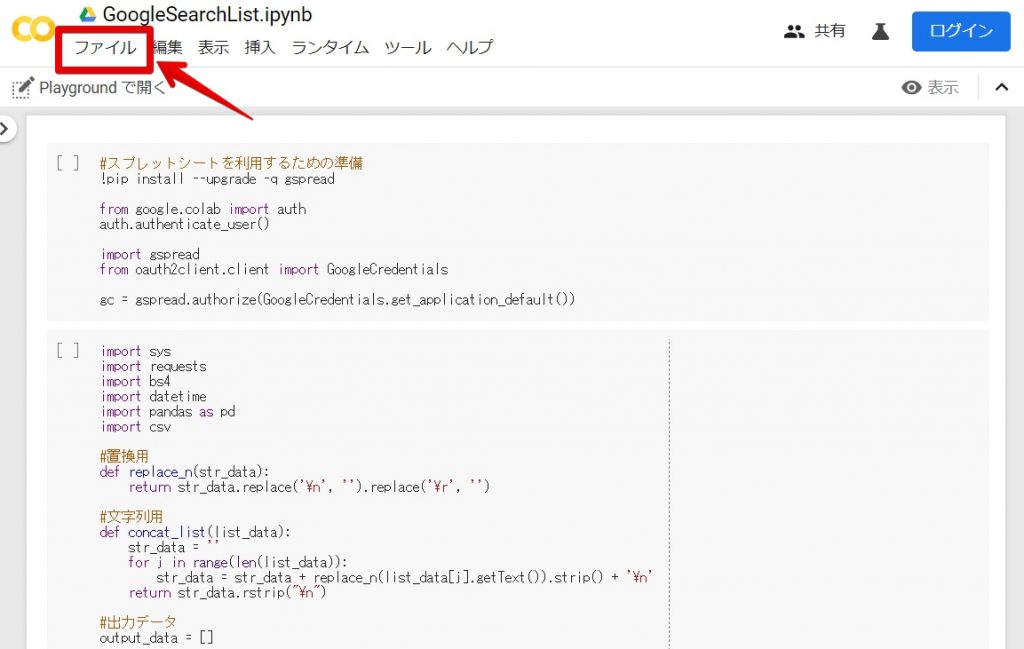
上記の通り、プログラムを開いたら、「ファイル」を押してください。
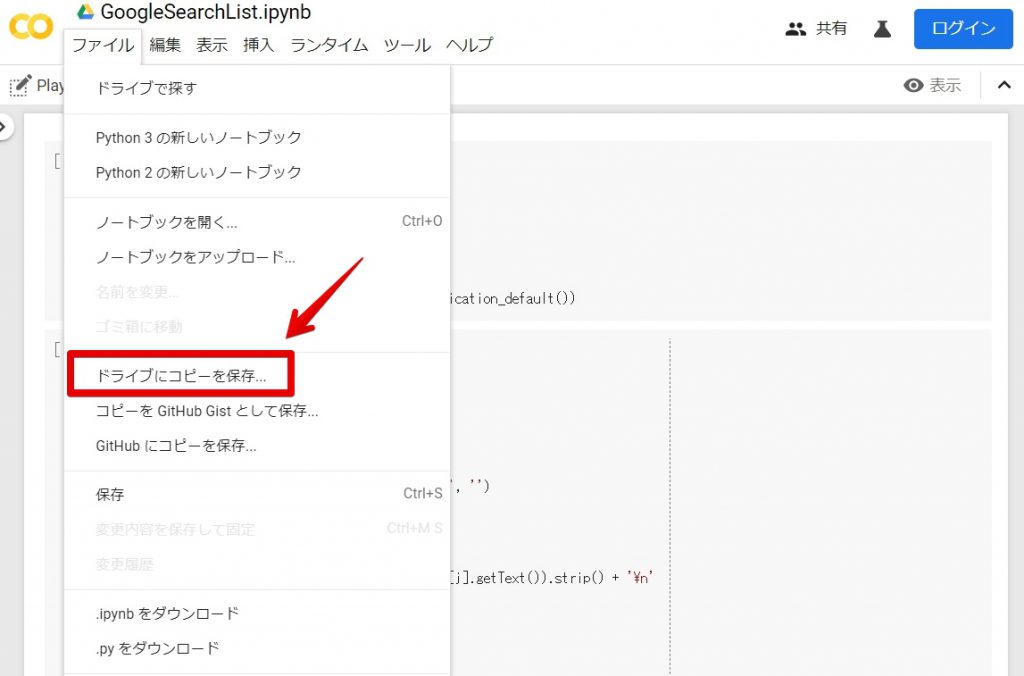
「ドライブにコピーを保存」を選択してください。
プログラムを実行する前の事前準備
Googleの検索結果をスクレイピングするプログラムを実行する前に事前準備をする必要があります。
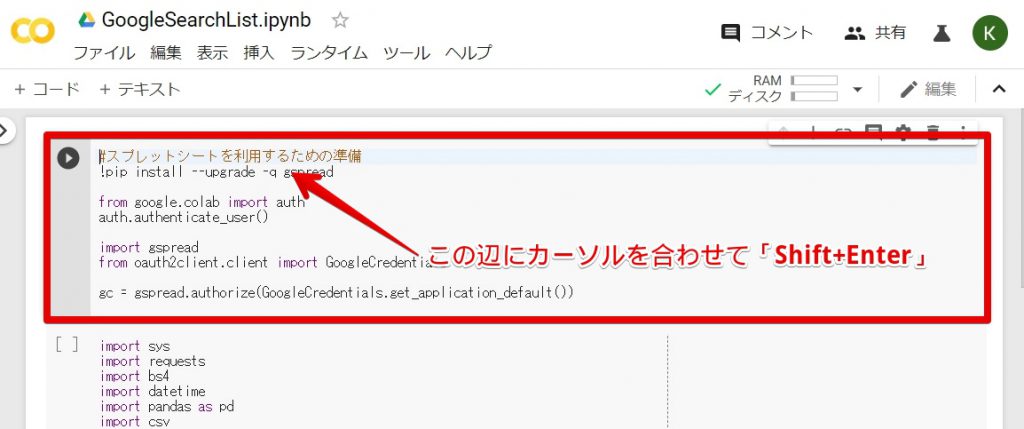
上記の画像の通り、「Shift+Enter」を押してください。
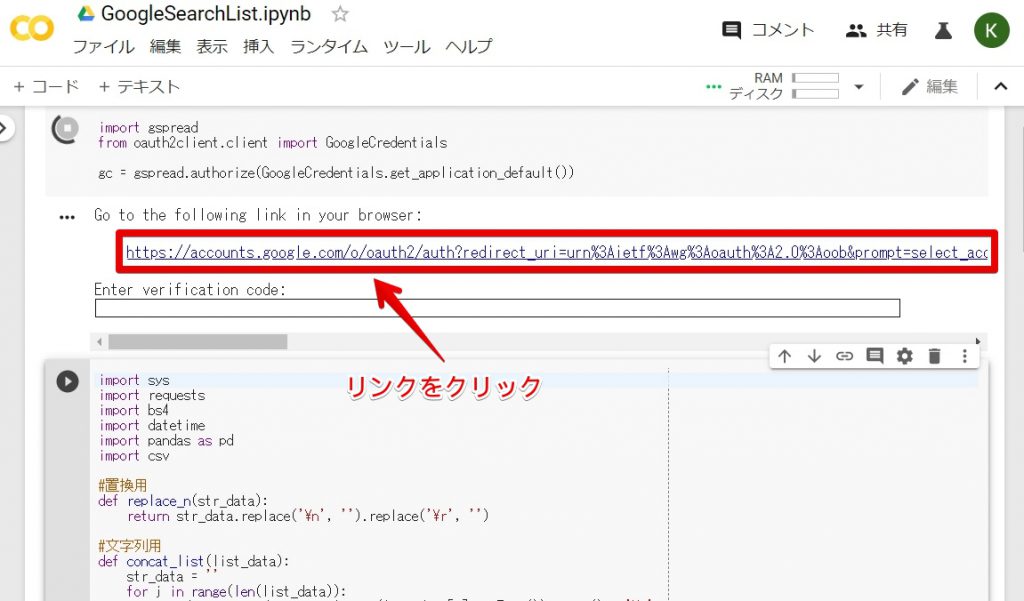
上記の画像の通り、リンクが表示されるのでクリックしてください。
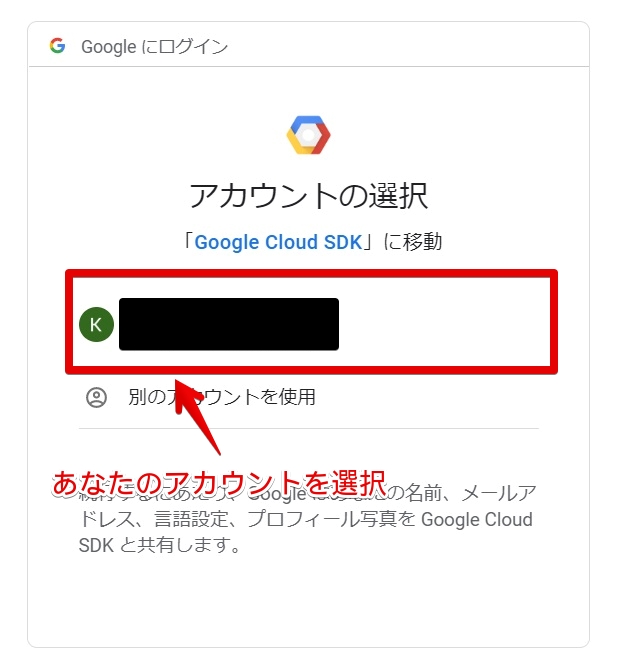
あなたのアカウントを選択してください。
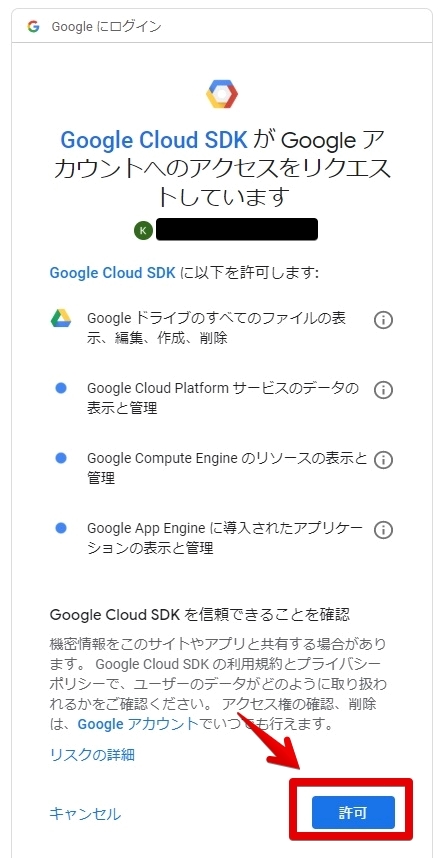
許可を押してください。
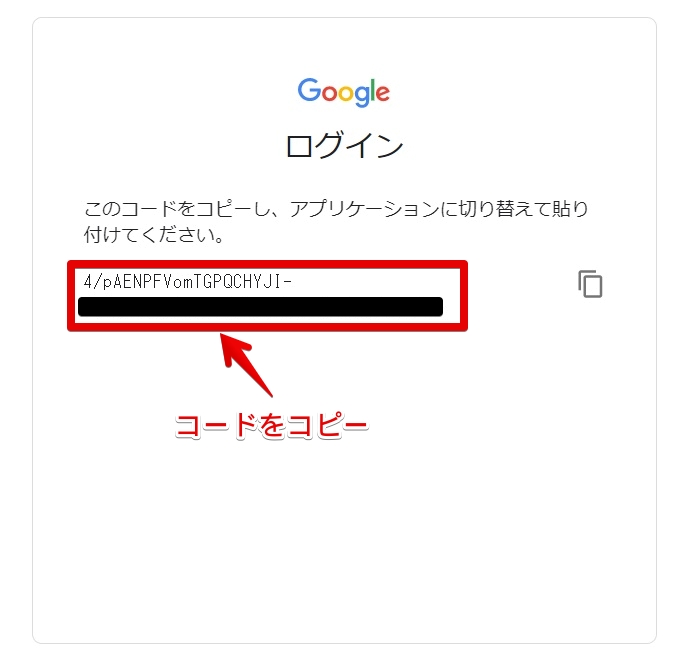
コードをコピーしてください。
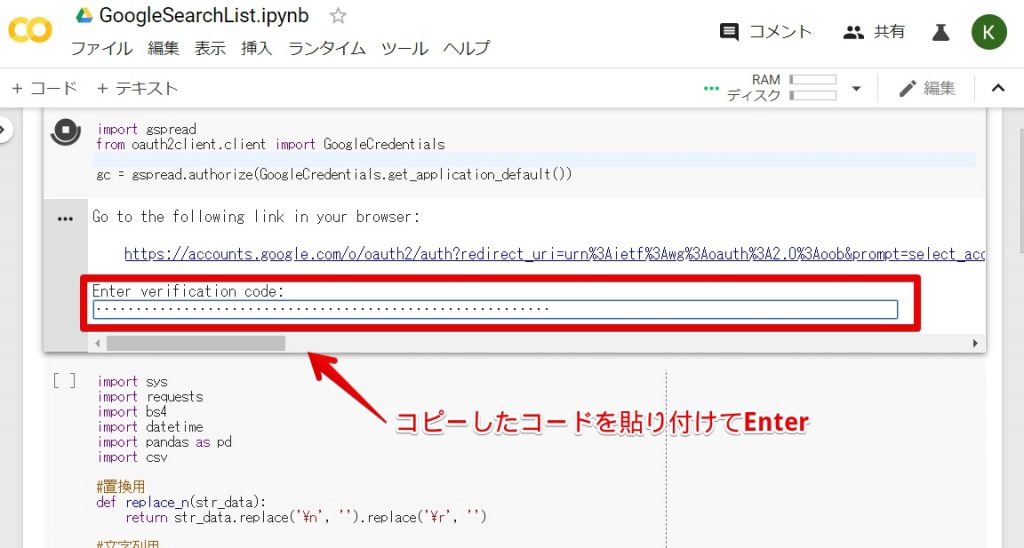
先ほどコピーしたコードを上記の通り、貼り付けてEnterを押してください。
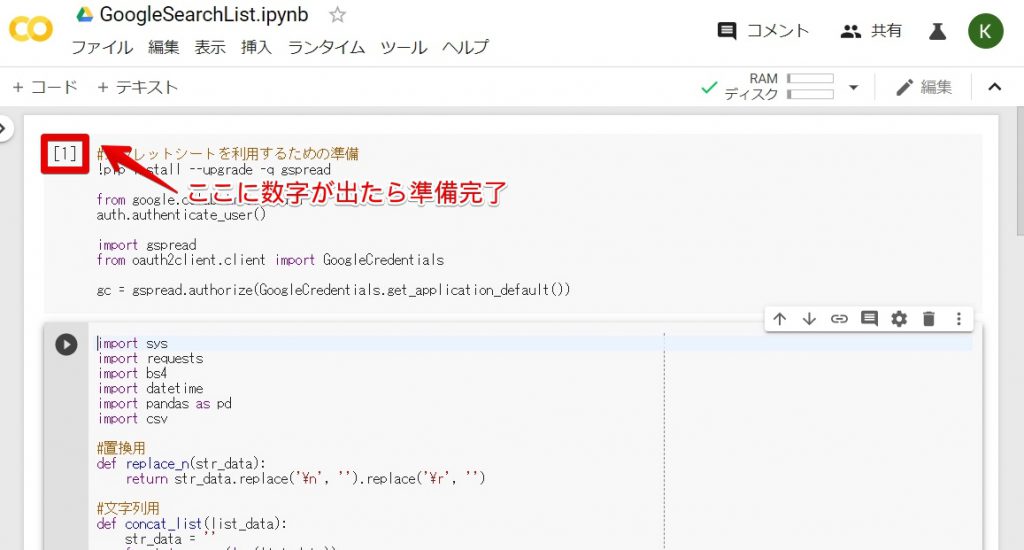
上記の通り、左の括弧に数値が出れば準備完了です。
キーワードを指定
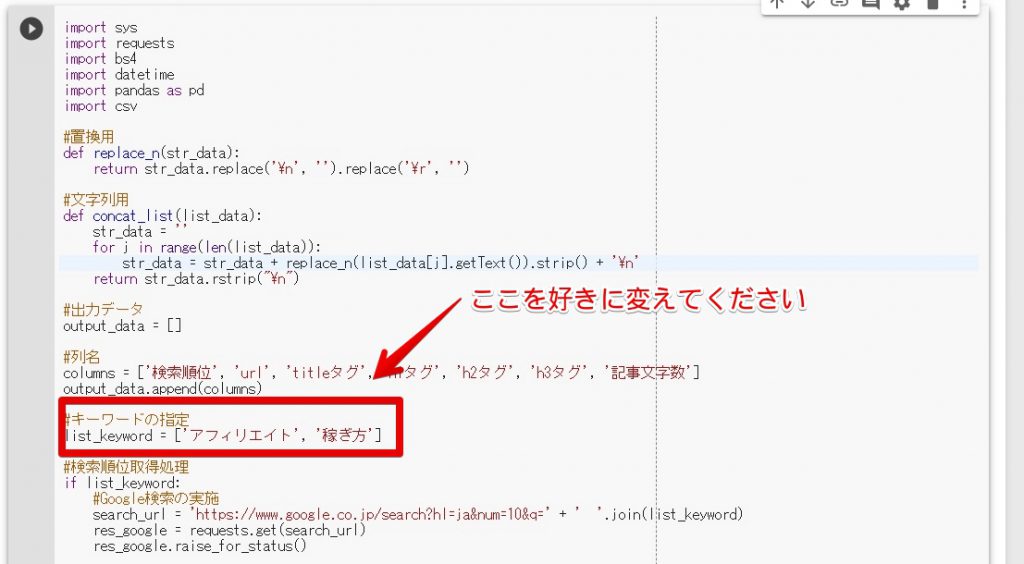
上記の画像の通り、分析したいキーワードに変更してください。
プログラムの実行
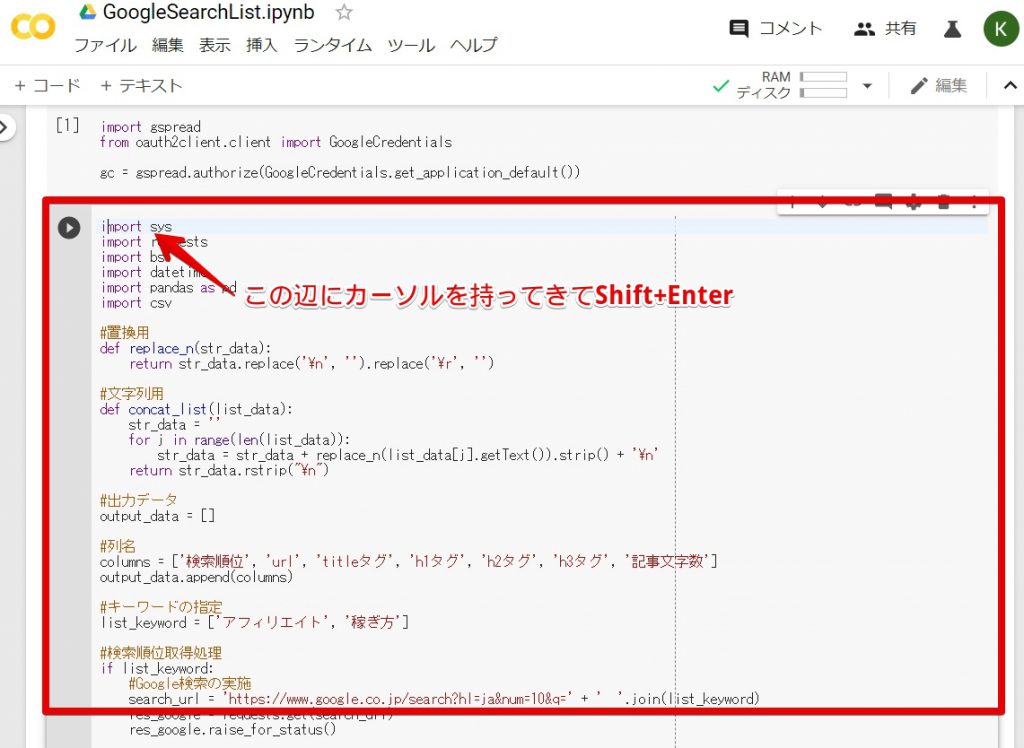
上記の通り、Shift+Enterをおしてください。
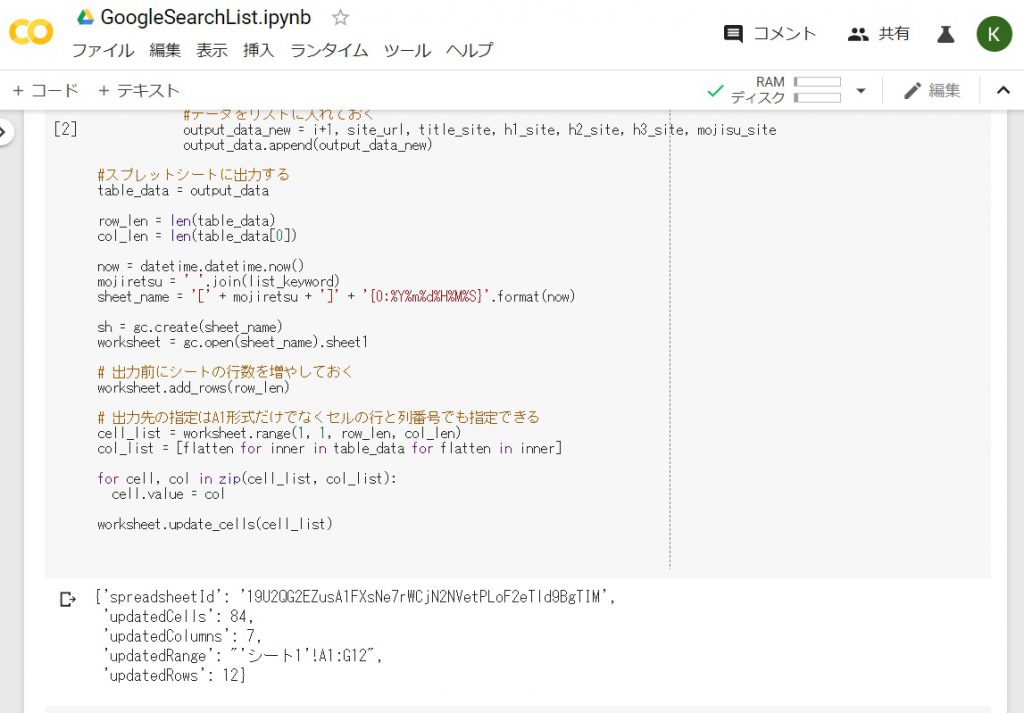
1、2分待てばおしまいです!
取得結果を確認
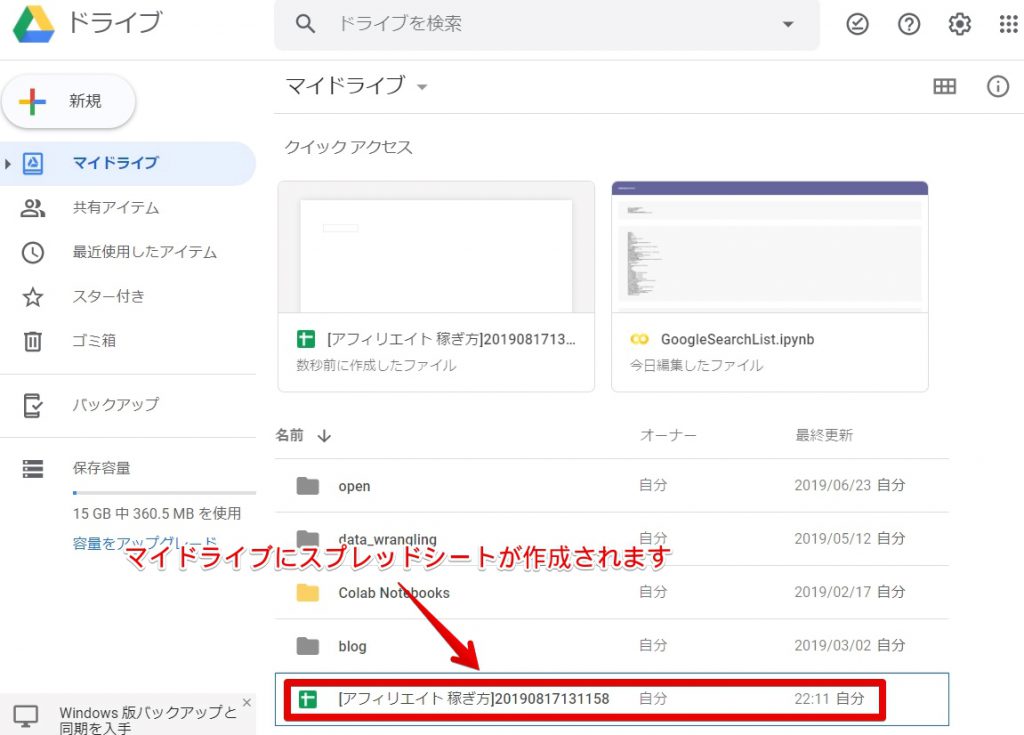
上記の画像の通り、あなたのマイドライブにスプレッドシートが作成されます。開いてみてください。
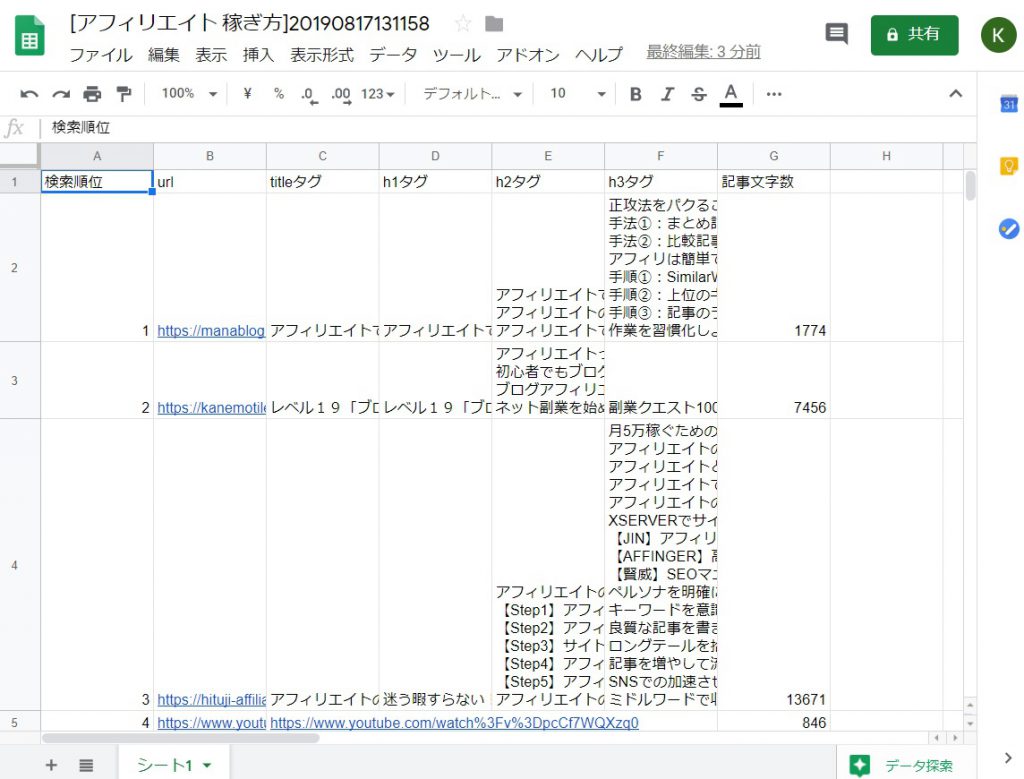
このままだと不格好なので、少し見やすくします。
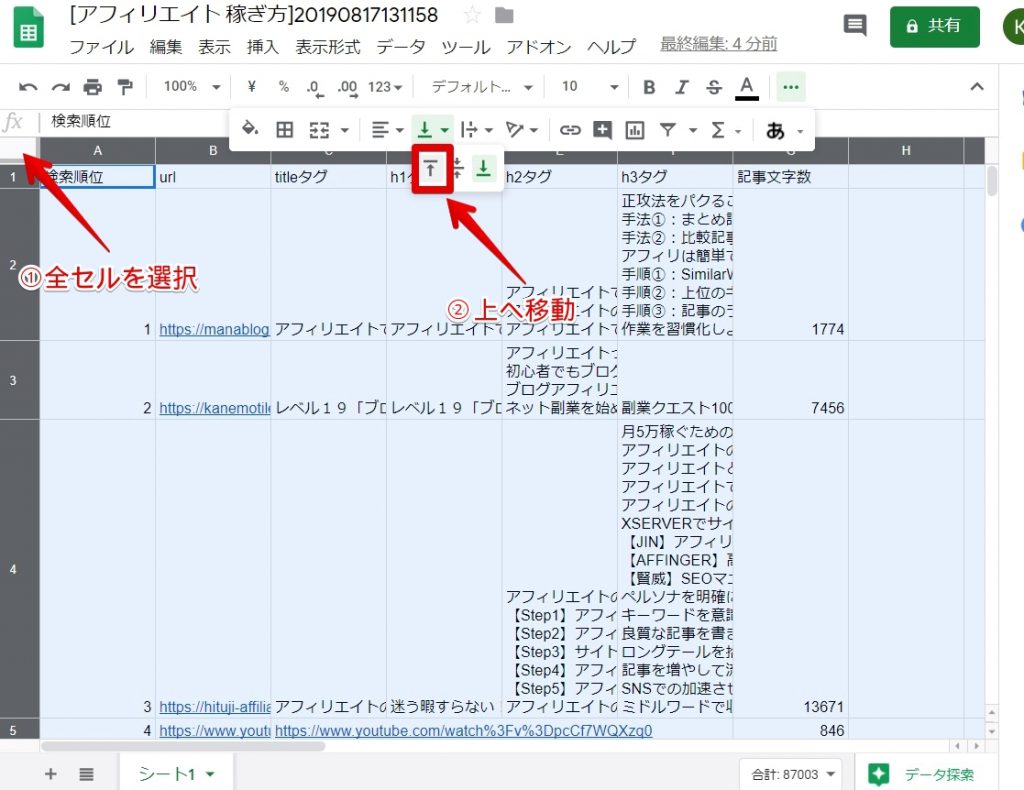
上記の通り、全セルを選択して、文字の位置を上へ移動しましょう。
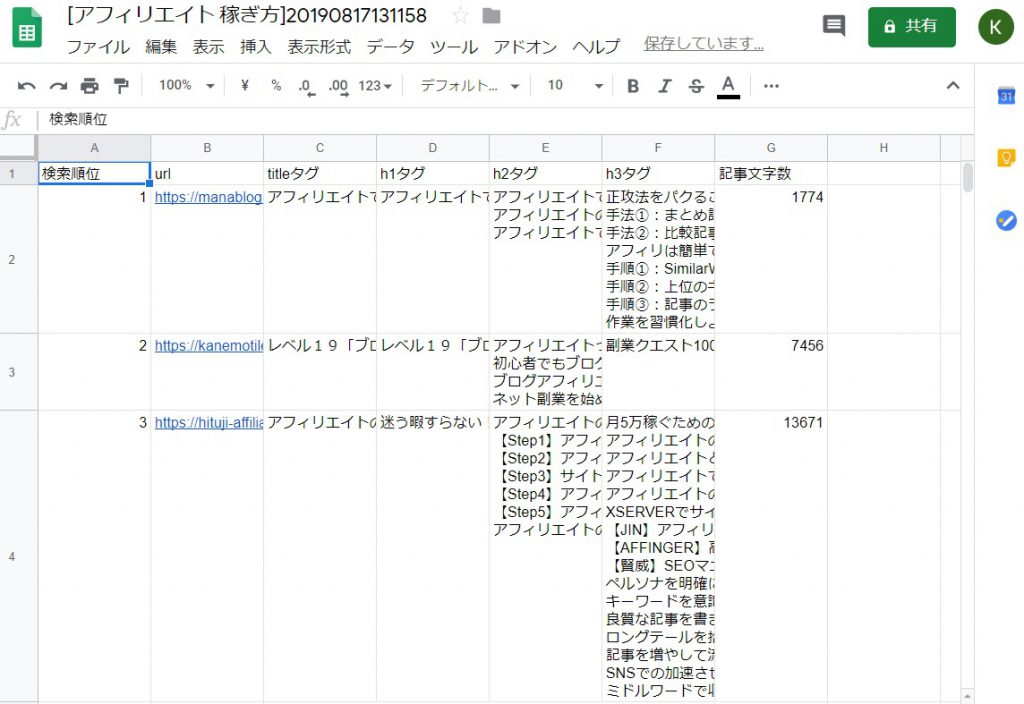
少し見やすくなりましたね。あとは適宜、横幅を調整したり、折り返し表示に変更したりしてください。
さいごに:競合サイト分析はかなり重要
本記事では、競合サイトを分析しているあなた向けに、Googleの検索結果上位サイトのtitleタグ、h1タグなどを自動取得するプログラムを無料公開しました。
これであなたも、競合サイトのデータ収集が楽になりますね!
競合サイトの分析はかなり重要なので、記事で紹介したプログラムが、あなたの役に立てば幸いです。
こんな感じで自分で作成したプログラムを公開しているので、ツイッターのフォローをお願いします。また、ブログを更新したら通知しています。
以上です。
参照元
本記事で公開したプログラムは下記の記事を参考に作成しました。



